
Introduction
This past semester we took a deep reinforcement learning course together at CMU. The class introduced us to goal-conditioned learning and Hindsight Experience Replay (HER). The underlying concepts behind HER interested us, and we wanted to try reproducing the authors’ results in sparse/binary reward environments - in our case, simulated reacher environments - benchmarked against vanilla TD3. We hope to illustrate the benefits of using hindsight experience in sparse, binary reward environments through sharing a discussion of our implementation, experimentation, and methods. While we won’t go in-depth into the implementation details, we hope that you come out of this with a better idea of why hindsight replay is so useful and interesting, and how we went about trying to prove it!
What is TD3?

TD3 is an off-policy RL method for continuous action spaces, which improves its predecessor, DDPG, by reducing overestimation bias and improving training stability. This generally results in higher performance than DDPG. We’re going to assume we all have a working knowledge of RL algorithms, but if you want to learn more then you can read more details about TD3 and DDPG here.
What is HER?

To understand HER, you’ll first need to understand regular experience replay (ER). ER involves learning from an agent’s memory, by storing past experiences (more specifically, transitions) in a replay buffer. Then, the agent trains on randomly sampled transitions from the replay buffer by “replaying” these transitions. Training on randomly sampled transitions rather than sequentially collected experience helps de-correlate training data and improves learning. You can learn more about it here.
Goal-conditioned learning generally means learning to reach a goal in addition to maximizing reward. Let’s illustrate this with a motivating example:
A soccer player successfully kicks the ball into the goal - this is obviously a helpful learning example, as the player learns to repeat their sequence of actions to achieve their goal. But what about if the ball lands, say, a foot away from the goalpost? We can “move” the goalpost to wherever the ball actually ended up, so the player learns to celebrate making goals rather than feeling sad that they did not make the original goal. This helps the soccer player learn how to score better overall.
HER leverages this concept by augmenting real experience collected for the replay buffer with hindsight about states the agent was actually able to reach. For example, let’s say Turtle Claire is trying to make a goal. If the goal is 3 cells away, traditional goal-conditioned experience replay would tell her to store each of these transitions in her replay buffer with the original goal state at cell 3 and no return (AKA a cumulative reward of 0), since she did not score a goal.
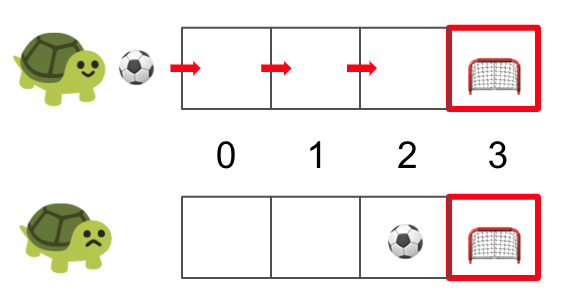
But with HER, Turtle Claire would also store each of these transitions with a goal state of cell 2 and positive return, since she would have scored had the goal been in cell 2. Even though this is not the original goal we wanted to achieve, we are still able to learn something useful by “moving the goalposts” in hindsight, which is the crux of HER.
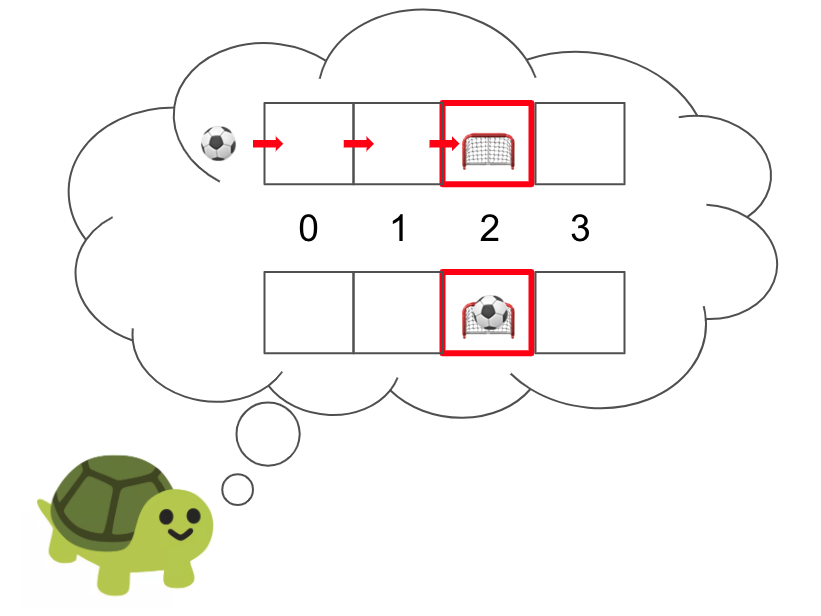
HER and goal-conditioned methods aim to solve the issue of learning in an environment with sparse rewards, which means very few states/actions in the environment actually give a positive or non-zero reward signal. Often, these sparse rewards are binary, as in Turtle Claire’s soccer scenario: you have either scored a goal, or you have not.
HER also helps with sample efficiency: since we augment our experience buffer with these goal-conditioned examples for replay, we have access to far more training data while using the same amount of examples drawn from the environment.
Why TD3 + HER?

If you read the HER paper, you’ll notice that the authors implemented HER with DDPG. We were wondering why they didn’t use TD3 instead, given that it’s a marked improvement on DDPG. After some digging, we found out that the HER paper came out one year before Fujimoto published his paper introducing TD3, which was a nice reminder of how quickly the field moves!

At any rate, poking around on Papers With Code and Google yielded re-implementations of the DDPG + HER results from the original paper. Although we did find some implementations of TD3+HER out there (like this, this, and this), our curiosity was sufficiently piqued by TD3 and HER that we wanted to do our own exploration of it.
Specifically, we wanted to see what would happen if we trained our agents using TD3 with HER, instead of standard ER (which TD3 was originally proposed with). Even though TD3 tends to perform better than DDPG by improving stability and reducing overestimation bias during training, we expect that it won’t be able to overcome difficulties with learning in sparse reward environments. This is where HER comes in.
Setup
We started with Fujimoto’s original TD3 implementation and added hindsight replay functionality on top of it. For more details, you can see our code here.
Our goal was to train the agent in two different variations of a sparse-reward environment: OpenAI’s FetchReach environment (designed for learning sparse reward), and a sparsification of OpenAI’s MuJoCo Reacher environment (a dense reward environment that we adapted into a sparse reward environment).
For both environments, we evaluated the corresponding robot arm’s performance trained on:
- vanilla TD3 in a sparse reward environment, which we will refer to as the Sparse TD3 agent
- TD3 + HER in a sparse reward environment, which we will refer to as the TD3+HER agent
- vanilla TD3 in a dense reward environment, which we will refer to as the Dense TD3 agent
We will describe the environments in more detail below.
FetchReach Environment

There is an awesome suite of sparse reward environments designed by OpenAI that work with HER already that were benchmarked on DDPG + HER.
This environment is arguably the simplest of this suite of sparse reward environments that OpenAI released. The goal of this environment is to control a 3 degree-of-freedom robotic arm to reach a block placed before it in 3D space. The block’s location is fixed throughout the episode (where an “episode” is one attempt to reach the goal, capped out at 50 timesteps), but is randomly generated at the start of each episode.
This environment is default-set to return a sparse reward: it will give a reward \(r_t\) of 0 at timestep \(t\) if the block is within \(\epsilon\) of goal state \(g\) after taking action \(a\) from state \(s\), and 0 reward if it is not:
\[r_t(s, a, g) = \left\{\begin{array}{ll} 0 & d(s, g) < \epsilon\\ -1 & \text{otherwise} \end{array} \right.\]The return \(R\) of one episode in the FetchReach environment is the cumulative reward over each timestep in the episode:
\[R = \sum_t r_t\]How do these formulas correspond to getting the robot arm to reach as close to the target block as possible? If we received an episode return \(R = -50\), this would imply that our robot arm was not within \(\epsilon\) of the block, or any goal state, throughout the entire episode. That’s not what we want! On the other hand, if we received an episode return \(R = 0\), this means that at every timestep in our episode, the robot arm was within \(\epsilon\) of the block, or any goal state, throughout the entire episode. This is what we want! Therefore, we want to train our TD3 agent to maximize cumulative reward and achieve close to 0 episode return.
Sparsified Reacher Environment

The Reacher-v2 OpenAI Gym environment is similar to FetchReach in that a robot arm must reach a goal object. However, it has a shaped reward function that includes distance to the goal object, as well as a reward penalty for extraneous robot arm movement, and only has two degrees of freedom. In addition, this environment is considered “solved” (i.e. the robot arm has reached the goal object) when the episode return is greater than -3.75.
OpenAI’s FetchReach environment was made specifically to benchmark goal-conditioned learning strategies, so we wanted to challenge our implementation to see if it could still solve an environment that wasn’t “born” to be sparse. Therefore, we figured that the Reacher-v2 OpenAI Gym environment, which has a similar goal to the FetchReach environment but was designed with a shaped reward signal in mind, would be a good candidate for sparsification. Therefore, we extended the MuJoCo Reacher environment in order to convert it to a sparse reward environment.

The main changes we made to the original Bullet environment were:
- Sparsifying the environment: the agent only gets a reward if it’s within some distance \(\epsilon\) of the target location, otherwise 0.
- Augment the existing standard replay buffer with the agent’s intended goal and goal-conditioned rewards. We used the HER authors’ “future” goal-choosing scheme, which means after each episode, a state \(s\) selected for hindsight replay would be stored with its goal being a uniform-randomly selected state that occurred after \(s\) in the episode.
Some prominent variations to the reward definition and HER training we tried were:
- Varying \(\epsilon\), or how “off” the agent can be from the goal and still receive reward for “achieving” the goal.
- Varying \(k\), the ratio of standard ER and HER-generated memory to store for replay.
- Including/excluding factors other than distance to goal in the reward function.
See the Appendix for a full description of these parameters, along with additional things we varied.
Results
FetchReach Environment Results



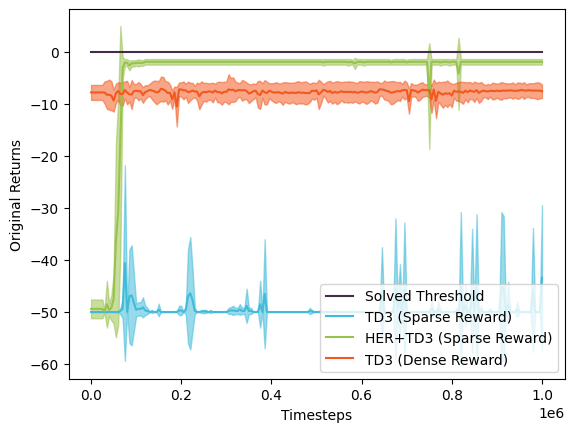
The verdict is in: including hindsight experience drastically improved the robot arm’s ability to reach the block! We can see that over 1 million timesteps, the poor sparse TD3 robot arm is unable to learn to reach the block at all. However, with HER, the TD3 + HER robot arm is able to consistently reach the block and achieve close to 0 episode returns within 200k timesteps.
| Vanilla TD3 Agent (Sparse Reward) |
TD3 + HER Agent (Sparse Reward) |
Vanilla TD3 Agent (Dense Reward) |
|
|---|---|---|---|
| \(\epsilon\) = 0.05 | 10% | 100% | 5% |
Using an epsilon of 0.05, the TD3 + HER agent successfully reached the goal 100% of the time. Meanwhile, the vanilla TD3 agent trained in a sparse reward environment only reached the goal 10% of the time.
Interestingly, the dense TD3 agent was unable to solve the environment. Its reward may be higher than that of sparse TD3 agent based on the plot above, but playing the recording back shows that it doesn’t appear to perform much better than the sparse TD3 agent.
Sparsified Reacher Environment Results



Although our sparsified environment was more difficult to solve than the FetchReach environment we had initially benchmarked, we were still able to perform far better than the sparse TD3 agent, which you can see above.
The best settings for the parameters listed in the Sparsified Reacher Environment section are:
- a linearly annealed \(\epsilon\) from 0.07 to 0.05
- storing a mixture of hindsight and regular experience
- using a -1/0 binary reward signal based on both distance to goal and action magnitude
We tracked the returns from our binary reward function, but we also computed the original returns under the environment’s original shaped reward (i.e. non-sparse, non-binary reward) to get a sense of how well our agent performed in the sparsified reacher environment. We can see that although the TD3+HER agent does not perform as well as the dense TD3 agent, it performs far better than the sparse TD3 agent. So, while the agent isn’t able to surpass the original “solved” reward threshold or match the performance in the original environment, it is clearly still able to learn something useful!
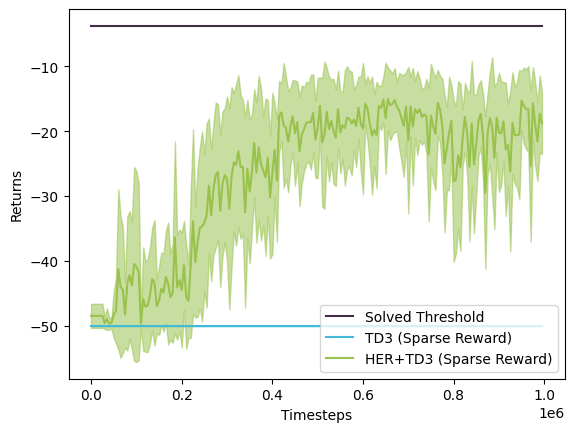
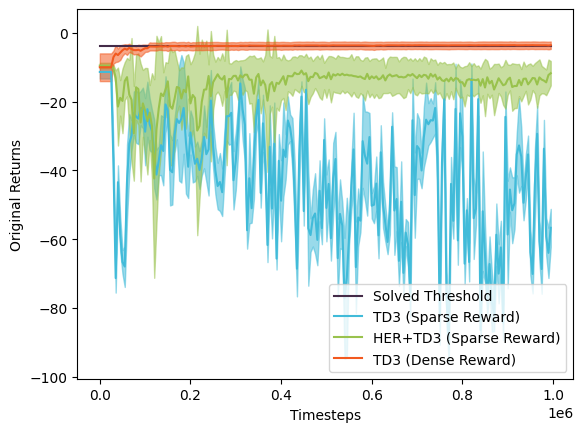
As we mentioned earlier, our best-performing TD3+HER agent was trained on an \(\epsilon\) linearly annealed from 0.07 to 0.05. When we benchmarked the final trained agent on our starting epsilon of 0.07, we discovered that it reached the goal 60% of the time. Meanwhile, benchmarking the final trained agent on our ending epsilon of 0.05 demonstrated that the agent reached the goal 50% of the time. Not sure about you, but we’d take those odds over the TD3 agent trained in a sparse reward environment any day of the week!
| Vanilla TD3 Agent (Sparse Reward) |
TD3 + HER Agent (Sparse Reward) |
Vanilla TD3 Agent (Dense Reward) |
|
|---|---|---|---|
| \(\epsilon\) = 0.07 | 0% | 60% | 100% |
| \(\epsilon\) = 0.05 | 0% | 50% | 100% |
Given the starting and ending epsilons we trained on, the TD3 + HER agent was able to reach the goal 50-60% of the time. Meanwhile, the vanilla TD3 agent trained in a sparse reward environment was never able to reach the goal for either epsilon, and the agent trained in the dense reward environment was always able to reach the goal for either epsilon.
Takeaways
-
Varying Epsilon: When defining our sparsified Reacher environment, the \(\epsilon\) determining the reward threshold played a large role in the agent’s learning - too large and the agent would too easily be within \(\epsilon\) of the goal and start to jitter around that area. Too small and even the goal-conditioned rewards would be too sparse for a HER agent to learn at all.
-
Parameters: In general (as is the case with any deep learning agent), we had lots of parameters to tune. Many of these (including \(\epsilon\)) arose from the fact that we were trying to modify an existing environment to get a binary reward function; the rest were mostly due to possible variations on HER implementations.
-
Sparsifying the Environment: HER was surprisingly effective at reaching the goal in a large percentage of episodes!
Conclusion
As our first (but hopefully not last) collab, we were super happy that our modifications to a SOTA algorithm achieved solid performance in binary, sparse-reward environments. We’re particularly excited that even after manually introducing reward sparsity to increase an environment’s difficulty, our agent still learned reasonably well, which confirmed our original hopes that introducing HER would significantly improve the learning achievable by TD3 alone. If you like, you can check out our code here! 🤪
We were initially drawn to goal-conditioned learning because it proves that even though you can’t achieve your loftier goals right now, there is intrinsic value in striving to achieve reachable goals in the present: you might learn something that helps you become successful in the future! Being able to prove this life lesson with an RL agent made this project extra satisfying for us.
If you have any questions, comments, or doubts, feel free to reach out to us via email, or drop your response below! This is a learning experience for us and we would love to receive feedback on how we could improve.
Resources
A huge, HUGE shoutout to Alex LaGrassa and Shreyas Chaudhari, who helped guide us at different parts throughout this entire journey.
In addition, we referenced a lot of great materials throughout the blogpost and while we were learning more about TD3 and HER! While these lists may not be exhaustive of all of that material, we hope that it is representative of it, and can be of use to someone else.
Papers
[1] Marcin Andrychowicz, et al. Hindsight Experience Replay (2018).
[2] Timothy P. Lillicrap, et al. Continuous control with deep reinforcement learning (2019).
[3] Scott Fujimoto, et al. Addressing Function Approximation Error in Actor-Critic Methods (2018).
[4] Matthias Plappert, et al. Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research (2018).
[5] Dhuruva Priyan G M, et al. Hindsight Experience Replay with Kronecker Product Approximate Curvature. (2020).
Other Resources
Appendix
The following is the full set of parameters for our sparsified Reacher experiments we performed:
- Varying \(\epsilon\) (the “threshold” maximum distance to goal at which the agent is rewarded).
- We also tried various annealing methods to decrease \(\epsilon\) over time, to try to nudge the agent closer and closer to the goal:
- Linear: \(\epsilon\) decrease by a fixed amount each episode
- Exponential: \(\epsilon\) decreased according to an exponential curve
- Step-wise: every x episodes would use a different \(\epsilon\)
- We also tried various annealing methods to decrease \(\epsilon\) over time, to try to nudge the agent closer and closer to the goal:
- Using Euclidean distance vs. each element-wise distance to measure goal proximity.
- Varying reward magnitudes (e.g., 0.1 vs. 1 for positive reward).
- Instead of positive reward, using a reward “penalty” for not reaching goal (0 reward if target reached, else -1).
- Varying the \(k\) parameter from the original HER paper, which controls the ratio of HER-selected vs. standard goal-conditioned ER replay memories.
- Storing both a standard ER and HER-generated memory for each transition (instead of using \(k\) above). In the original paper, for any given episode, \(\frac{k}{k+1}\) transitions would be stored with a HER-selected goal, and the rest are stored with the original intended goal. Here, we also tried storing all transitions with the original goal and a HER-selected goal.
- Electricity cost threshold: the agent only gets a reward for reaching the goal and if it doesn’t exceed this electricity threshold.
It’s also worth noting that we initially tried sparsifying the Pybullet reimplementation of MuJoCo Reacher, since we wanted to be able to train without a MuJoCo license. However, we found that the MuJoCo environment was much more amenable to learning over time and ultimately chose to extend the MuJoCo environment instead.